概述
基于Java,将pdf转成单一的tiff文件。
MAVEN依赖
以下是依赖在maven中心仓库中可以找到
<groupId>com.sun.media</groupId>
<artifactId>jai_codec</artifactId>
<version>1.1-mr</version>
</dependency>
<dependency>
<groupId>javax.media</groupId>
<artifactId>jai_core</artifactId>
<version>1.1-mr</version>
</dependency>
<dependency>
<groupId>com.sun.medialib</groupId>
<artifactId>mlibwrapper_jar</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.0-RC2</version>
</dependency>
实现
类图
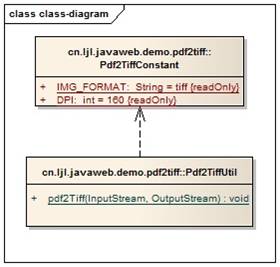
类属性和方法简介
- Pdf2TiffConstant
IMG_FORMAT :默认的图片格式
DPI :默认的转换精度
- Pdf2TiffUtil
public static pdf2Tiff (is: InputStream, os: OutputStream): void
将指定的pdf转成单一tiff文件,写到指定的输出流。参数is提供pdf文档的内容,参数os指定输出流。
代码
- Pdf2TiffConstant
package cn.ljl.javaweb.demo.pdf2tiff;
public class Pdf2TiffConstant {
/** 图片格式 */
public static final String IMG_FORMAT = "tiff";
/** 打印精度设置 */
public static final int DPI = 160; //图片的像素
}
- Pdf2TiffUtil
import static cn.ljl.javaweb.demo.pdf2tiff.Pdf2TiffConstant.DPI;
import static cn.ljl.javaweb.demo.pdf2tiff.Pdf2TiffConstant.IMG_FORMAT;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.List;
import javax.media.jai.JAI;
import javax.media.jai.PlanarImage;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;
import com.sun.media.jai.codec.ImageCodec;
import com.sun.media.jai.codec.ImageEncoder;
import com.sun.media.jai.codec.TIFFEncodeParam;
public class Pdf2TiffUtil {
/**
* 从输入流读取pdf,转化为tiff后写入输出流.<br/>
* 参考列表:
* <ol>
* <li><a href=
* "http://www.coderanch.com/t/497492/java/java/Convert-PDF-files-Tiff-files"
* >Convert PDF files to Tiff files</a></li>
* <li><a href=
* "http://www.oracle.com/technetwork/cn/java/javaee/downloads/readme-1-1-2-137176.html"
* >Java(TM) Advanced Imaging API README</a></li>
* </ol>
*
* @param is
* 输入流,提供pfg内容.
* @param os
* 输出流.
*/
public static void pdf2Tiff(InputStream is, OutputStream os) {
PDDocument doc = null;
try {
doc = PDDocument.load(is);
int pageCount = doc.getNumberOfPages();
PDFRenderer renderer = new PDFRenderer(doc); // 根据PDDocument对象创建pdf渲染器
List<PlanarImage> piList = new ArrayList<PlanarImage>(pageCount - 1);
for (int i = 0 + 1; i < pageCount; i++) {
BufferedImage image = renderer.renderImageWithDPI(i, DPI,
ImageType.RGB);
PlanarImage pimg = JAI.create("mosaic", image);
piList.add(pimg);
}
TIFFEncodeParam param = new TIFFEncodeParam();// 创建tiff编码参数类
param.setCompression(TIFFEncodeParam.COMPRESSION_DEFLATE);// 压缩参数
param.setExtraImages(piList.iterator());// 设置图片的迭代器
BufferedImage fimg = renderer.renderImageWithDPI(0, DPI,
ImageType.RGB);
PlanarImage fpi = JAI.create("mosaic", fimg); // 通过JAI的create()方法实例化jai的图片对象
ImageEncoder enc = ImageCodec.createImageEncoder(IMG_FORMAT, os,
param);
enc.encode(fpi);// 指定第一个进行编码的jai图片对象,并将输出写入到与此
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (doc != null)
doc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}