- 术语
- 1.设置MAVEN_OPTS环境变量
- 2.配置用户范围settings.xml
- 3.不要使用IDE内嵌的Maven
- 4.搭建本地仓库管理器
- 5.尽可能的遵循Maven的约定
- 6.优先编译被依赖的模块
- 7.利用Maven插件创建项目
- 8.降低依赖重复
- 9.使用Maven Dependency插件进行优化
- 参考资料
术语
快照版:开发过程中的不稳定版本,开发阶段使用
发布版:稳定的发行版本,测试、部署阶段使用
1.设置MAVEN_OPTS环境变量
当Maven项目很大,或者你运行诸如 mvn site 这样的命令的时候,maven运行需要很大的内存,在默认配置下,就可能遇到java的堆溢出,报OutOfMemoryError错误。解决的方法是调整java的堆大小的值。
Windows环境中:
找到文件%M2_HOME%\bin\mvn.bat ,这就是启动Maven的脚本文件,在该文件中你能看到有一行注释为:
@REM set MAVEN_OPTS=-Xdebug -Xnoagent -Djava.compiler=NONE...
它的意思是你可以设置一些Maven参数,我们就在注释下面加入一行:
set MAVEN_OPTS= -Xms128m -Xmx512m
之后,当你运行Maven命令如: mvn -version 查看配置是否生效。
2.配置用户范围settings.xml
Maven用户可以选择配置$M2_HOME/conf/settings.xml或者${user.home}/.m2/settings.xml。前者是全局范围的,整台机器上的所有用户都会直接收到该配置的影响,而后者是用户范围的,只有当前用户才会收到该配置的影响。
我们推荐使用用户范围的settings.xml,主要是为了避免无意识地影响到系统中其他用户,当然,如果你有切实的需求,需要统一系统中所有用户的settings.xml配置,则当然应该使用全局范围的settings.xml。
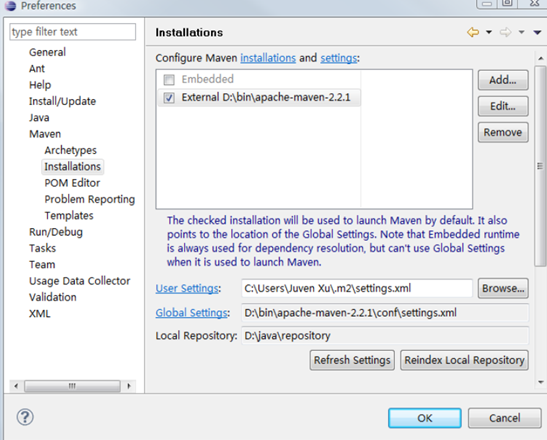
3.不要使用IDE内嵌的Maven
不论是Eclipse还是NetBeas,当我们集成Maven的时候,都会安装上一个内嵌的Maven,如果即使用IDE的Maven,也使用命令行的Maven,这样由于版本不一致,容易造成构建行为的不一致,所以我们可以在IDE中配置Maven插件使用外部的Maven。
以下是Eclipse中选择这一个外部的Maven的方法。如下图:
4.搭建本地仓库管理器
搭建本地仓库的好处:
1.通过为所有的来自中央Maven仓库的构件安装一个本地的缓存,你将加速组织内部的所有构建,所以通过本地仓库提供Maven依赖服务可以节省时间和带宽。
2.仓库管理器为组织提供了一种控制Maven下载的机制,你可以详细的设置从公开仓库包含或排除特定的构件。
3.Nexus的仓库可以管理项目的多个版本(快照版、发布版),方便了开发。
5.尽可能的遵循Maven的约定
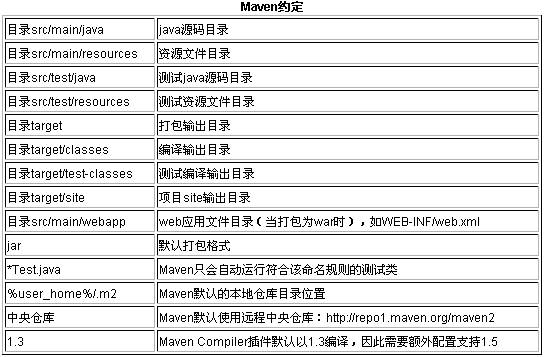
使用Maven的时候,你应该尽可能遵循它的配置约定,一方面可以简化配置,另一方面可建立起一种标准,减少交流学习成本。
其实基本上所有的约定,或者说默认配置,都可以在Maven的超级POM(super pom)中找到。由于所有的POM都继承了这个超级POM(类似于java中所有类都继承于Object),因此它的默认配置就被继承了。以Maven 2.0.9为例,你可以在%m2_home%/lib/下看到一个名为maven-2.0.9-uber.jar的文件,打开这个文件,可以找到org /apache/maven/project/pom-4.0.0.xml这个文件,这就是超级POM。
6.优先编译被依赖的模块
假设一个项目C有两个模块,模块A和模块B,其中模块A依赖模块B。若你直接编译项目C,Maven本应该先编译模块B,再编译模块A,因为模块A依赖模块B。但是不幸的是,Maven这方面支持的并不是那么完美。所以如果模块B有改动,我们应该先编译模块B,再编译整个项目C。希望Maven会在未来的版本中改进这个问题。
7.利用Maven插件创建项目
当我们需要创建一个基于Maven的项目时,我们可以有两种选择。一种是遵循Maven约定,自己创建项目需要的所有目录和文件(例如pom.xml),但是这种方式是不被推荐的。因为这种方式需要手动,而我们往往容易在不经意中犯下错误(例如拼写错误)。我们可以利用Maven的IDE插件(例如m2eclipse)创建一个基于Maven的项目,这种方式会自动生成Maven项目标准的目录和文件。
8.降低依赖重复
- 上移共同的依赖至父pom.xml的<dependencyManagement>
如果多于一个项目依赖于一个特定的依赖,你可以在<dependencyManagement>中列出这个依赖。父POM包含一个版本和一组排除配置,所有的子POM需要使用<groupId>和<artifactId>引用这个依赖。如果依赖已经在<dependencyManagement>中列出,子项目可以忽略版本和排除配置。
- 为兄弟项目使用内置的项目<version>和<groupId>
如果多个相关的依赖的版本都是相同的,可以使用properties元素定义Maven属性,依赖的版本值用这一属性引用表示。
<properties>
<spring.groupId >org.springframework</spring.groupId>
<spring.version>2.5.6</spring.version>
</properties>
<dependencies>
<dependency>
<groupId>${spring.groupId}</groupId>
<artifactId>spring</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>${spring.groupId}</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
</dependencies>
9.使用Maven Dependency插件进行优化
$ mvn dependency:analyze : 分析这个项目,查看是否有直接依赖(在pom.xml显式声明的依赖但没有被引用过),或者一些使用了但不是在pom.xml显式声明的依赖
$ mvn dependency:tree:列出项目中所有的直接和传递性依赖
通过以上两条命令来移除那些未使用,但声明的依赖,以及显示声明使用了,但未声明的依赖。
参考资料
-
MAVEN使用最佳实践 闫国玉
-
好书:《Maven权威指南中文版》