以下记录下在阅读《阿里巴巴java开发手册》规范里感觉有用但自己还没做到或没地方施展的一些开发规范,但想看完整版的朋友可以到网上找。
一、编程规约
- 1.常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包内共享常量、类内共享常量。
1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 const 目录下。
2) 应用内共享常量:放置在一方库的 modules 中的 const 目录下。
反例: 易懂变量也要统一定义成应用内共享常量,两位攻城师在两个类中分别定义了表示“ 是” 的变量:
类 A 中: public static final String YES = “yes”;
类 B 中: public static final String YES = “y”;
A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致产生线上问题。
3) 子工程内部共享常量:即在当前子工程的 const 目录下。
4) 包内共享常量:即在当前包下单独的 const 目录下。
5) 类内共享常量:直接在类内部 private static final 定义。
- 2.单行字符数限制不超过 120 个,超出需要换行,换行时,遵循如下原则:
1) 换行时相对上一行缩进 4 个空格。
2) 运算符与下文一起换行。
3) 方法调用的点符号与下文一起换行。
4) 在多个参数超长,逗号后进行换行。
5) 在括号前不要换行
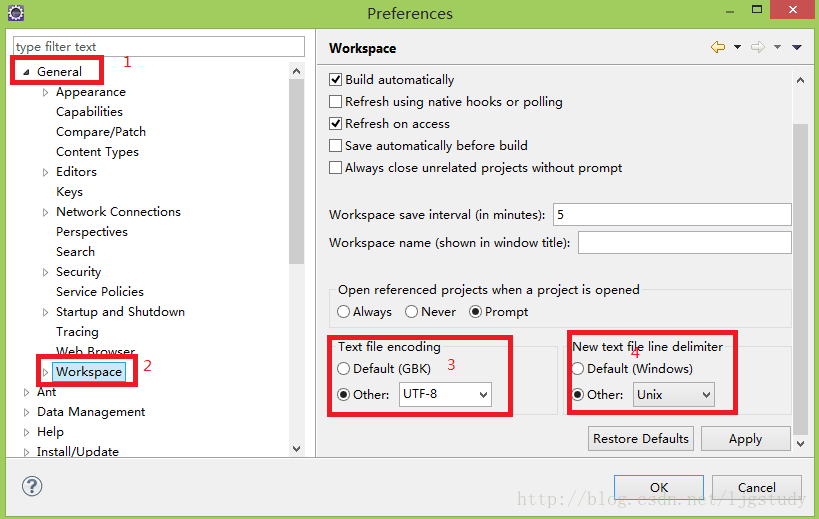
- 3.IDE 的 text file encoding 设置为 UTF-8; IDE 中文件的换行符使用 Unix 格式,不要使用 windows 格式
-
4.对外暴露的接口签名, 原则上不允许修改方法签名,避免对接口调用方产生影响。接口过时必须加@Deprecated 注解,并清晰地说明采用的新接口或者新服务是什么
-
5.关于基本数据类型与包装数据类型的使用标准如下:
1) 所有的 POJO 类属性必须使用包装数据类型。
2) RPC 方法的返回值和参数必须使用包装数据类型。
3) 所有的局部变量推荐使用基本数据类型。
说明: POJO 类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何NPE 问题,或者入库检查,都由使用者来保证。
正例: 数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险。
反例: 某业务的交易报表上显示成交总额涨跌情况,即正负 x%, x 为基本数据类型,调用的RPC 服务,调用不成功时,返回的是默认值,页面显示: 0%,这是不合理的,应该显示成中划线-。所以包装数据类型的 null 值,能够表示额外的信息,如:远程调用失败,异常退出
- 6.结合第5点,定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
反例: 某业务的 DO 的 gmtCreate 默认值为 new Date();但是这个属性在数据提取时并没有置入具体值,在更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间
- 7.序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值。
说明: 注意 serialVersionUID 不一致会抛出序列化运行时异常
- 8.POJO 类必须写 toString 方法,可使用工具类 source> generate toString 时。如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
说明: 在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
- 9.循环体内,字符串的联接方式,使用 StringBuilder 的 append 方法进行扩展
反例:
String str = "start";
for(int i=0; i<100; i++){
str = str + "hello";
}
说明: 反编译出的字节码文件显示每次循环都会 new 出一个 StringBuilder 对象,然后进行append 操作,最后通过 toString 方法返回 String 对象,造成内存资源浪费
- 10.类成员与方法访问控制从严:
1) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。
2) 工具类不允许有 public 或 default 构造方法。
3) 类非 static 成员变量并且与子类共享,必须是 protected。
4) 类非 static 成员变量并且仅在本类使用,必须是 private。
5) 类 static 成员变量如果仅在本类使用,必须是 private。
6) 若是 static 成员变量,必须考虑是否为 final。
7) 类成员方法只供类内部调用,必须是 private。
8) 类成员方法只对继承类公开,那么限制为 protected。
说明: 任何类、方法、参数、变量,严控访问范围。过宽泛的访问范围,不利于模块解耦。思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 Service 方法,或者一个 public 的成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的视线内,变量作用域太大,如果无限制的到处跑,那么你会担心的
- 11.使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
说明: asList()返回的是内部的ArrayList,而此类没有实现父类AbstractArrayList的add()方法。 Arrays.asList体现的是适配器模式,只是转换接口,后台的数据仍是数组。
String[] str = new String[] { "a", "b" };
List list = Arrays.asList(str);
第一种情况: list.add("c"); 运行时异常。
第二种情况: str[0]= "gujin"; 那么 list.get(0)也会随之修改。
- 12.在 JDK7 版本以上, Comparator 要满足自反性,传递性,对称性,不然 Arrays.sort,Collections.sort 会报 IllegalArgumentException 异常。
说明:
1) 自反性: x, y 的比较结果和 y, x 的比较结果相反。
2) 传递性: x>y,y>z,则 x>z。
3) 对称性: x=y,则 x,z 比较结果和 y, z 比较结果相同。
反例: 下例中没有处理相等的情况,实际使用中可能会出现异常:
new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getId() > o2.getId() ? 1 : -1;
}
}
- 13.合理利用好集合的有序性(sort)和稳定性(order),避免集合的无序性(unsort)和不稳定性(unorder)带来的负面影响。
说明: 稳定性指集合每次遍历的元素次序是一定的。有序性是指遍历的结果是按某种比较规则依次排列的。如: ArrayList 是 order/unsort; HashMap 是 unorder/unsort; TreeSet 是order/sort。
- 14.SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为static,必须加锁,或者使用 DateUtils 工具类。
正例: 注意线程安全,使用 DateUtils。亦推荐如下处理:
private static final ThreadLocal<DateFormat> df = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
};
说明: 如果是 JDK8 的应用,可以使用 instant 代替 Date, Localdatetime 代替 Calendar,Datetimeformatter 代替Simpledateformatter,官方给出的解释: simple beautiful strongimmutable thread-safe
- 15.并发修改同一记录时,避免更新丢失,要么在应用层加锁,要么在缓存加锁,要么在数据库层使用乐观锁,使用 version 作为更新依据
说明: 如果每次访问冲突概率小于 20%,推荐使用乐观锁,否则使用悲观锁。乐观锁的重试次 数不得小于 3 次。
-
16.多线程并行处理定时任务时, Timer 运行多个 TimeTask 时,只要其中之一没有捕获抛出的异常,其它任务便会自动终止运行,使用 ScheduledExecutorService 则没有这个问题。
-
17.线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors 各个方法的弊端:
1) newFixedThreadPool 和 newSingleThreadExecutor:主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。
2) newCachedThreadPool 和 newScheduledThreadPool:主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
- 18.使用 CountDownLatch 进行异步转同步操作,每个线程退出前必须调用 countDown 方法,线程执行代码注意 catch 异常,确保 countDown 方法可以执行,避免主线程无法执行至countDown 方法,直到超时才返回结果。
说明: 注意,子线程抛出异常堆栈,不能在主线程 try-catch 到。
-
19.注意 HashMap 的扩容死链,导致 CPU 飙升的问题
-
20.ThreadLocal 无法解决共享对象的更新问题,ThreadLocal 对象建议使用 static 修饰。这个变量是针对一个线程内所有操作共有的,所以设置为静态变量,所有此类实例共享此静态变量 ,也就是说在类第一次被使用时装载,只分配一块存储空间,所有此类的对象(只要是这个线程内定义的)都可以操控这个变量
-
21.volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。如果想取回 count++数据,使用如下类实现:AtomicInteger count = new AtomicInteger(); count.addAndGet(1); count++操作如果是JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数)
-
22.推荐尽量少用 else,如果使用要 if-else if-else 方式表达逻辑,【强制】请勿超过 3 层,超过请使用状态设计模式
-
23.循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、获取数据库连接,进行不必要的 try-catch 操作(这个 try-catch 是否可以移至循环体外)
-
24.写完方法后或方法更新后,需要去补充注释,所有的抽象方法(包括接口中的方法)必须要用 javadoc注释、除了返回值、参数、异常说明外,还必须指出该方法做什么事情,实现什么功能。如有实现和调用注意事项,请一并说明
-
25.注释掉的代码尽量要配合说明,而不是简单的注释掉。
说明: 代码被注释掉有两种可能性:
1)后续会恢复此段代码逻辑。
2)永久不用。前者如果没有备注信息,难以知晓注释动机。后者建议直接删掉(代码仓库保存了历史代码)
- 26.特殊注释标记,请注明标记人与标记时间。注意及时处理这些标记,通过标记扫描,经常清理此类标记。线上故障有时候就是来源于这些标记处的代码。
1) 待办事宜( TODO) :(标记人,标记时间, [预计处理时间])
2) 错误,不能工作( FIXME) :(标记人,标记时间, [预计处理时间])
- 27.velocity 调用 POJO 类的属性时,建议直接使用属性名取值即可,模板引擎会自动按规范调用 POJO 的 getXxx(),如果是 boolean 基本数据类型变量(注意, boolean 命名不需要加 is 前缀),会自动调用 isXxx()方法。
说明: 注意如果是 Boolean 包装类对象,优先调用 getXxx()的方法。
二、异常日志
-
1.对大段代码进行 try-catch,这是不负责任的表现。 catch 时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分异常类型,再做对应的异常处理
-
2.finally 块必须对资源对象、流对象进行关闭,有异常也要做 try-catch。
说明: 如果 JDK7,可以使用 try-with-resources 方法。
- 3.方法的返回值可以为 null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回 null 值。调用方需要进行 null 判断防止 NPE 问题。
说明: 本规约明确防止 NPE 是调用者的责任。即使被调用方法返回空集合或者空对象,对调用者来说,也并非高枕无忧,必须考虑到远程调用失败,运行时异常等场景返回 null 的情况
- 4.防止 NPE,是程序员的基本修养,注意 NPE 产生的场景:
1) 返回类型为包装数据类型,有可能是 null,返回 int 值时注意判空。
2) 数据库的查询结果可能为 null。字段存储null值或取不到取对象默认值null
3) 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null。hashmap的key/value、hashtable的value都允许为null
4) 远程调用返回对象,一律要求进行 NPE 判断。
5) 对于 Session 中获取的数据,建议 NPE 检查,避免空指针。
6) 级联调用 obj.getA().getB().getC();一连串调用,易产生 NPE
- 5.在代码中使用“ 抛异常” 还是“ 返回错误码” ,对于公司外的 http/api 开放接口必须使用“ 错误码”;而应用内部推荐异常抛出;跨应用间 RPC 调用优先考虑使用 Result 方式,封装 isSuccess、 “ 错误码” 、 “ 错误简短信息” 。
说明: 关于 RPC 方法返回方式使用 Result 方式的理由:
1)使用抛异常返回方式,调用方如果没有捕获到就会产生运行时错误。
2)如果不加栈信息,只是 new 自定义异常,加入自己的理解的 error message,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。
- 6.应用中的扩展日志(如打点、临时监控、访问日志等)命名方式:appName_logType_logName.log。logType:日志类型,推荐分类有 stats/desc/monitor/visit等;logName:日志描述。这种命名的好处:通过文件名就可知道日志文件属于什么应用,什么类型,什么目的,也有利于归类查找。
正例: mppserver 应用中单独监控时区转换异常,如:mppserver_monitor_timeZoneConvert.log
说明: 推荐对日志进行分类,业务日志、数据库日志、第三方插件日志、缓存日志等尽量分开存放,便于开发人员查看,也便于通过日志对系统进行及时监控。
- 7.异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么往上抛。
正例: logger.error(各类参数或者对象 toString + “_” + e.getMessage(), e);
- 8.可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。注意日志输出的级别, error级别只记录系统逻辑出错、异常、或者重要的错误信息。如非必要,请不要在此场景打出 error级别,避免监控日志的应用频繁报警。推荐开发环境、测试环境应该一套日志级别(info、warn、error),生产环境一套日志级别(warn、error)
说明: 大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。纪录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
三、数据库规约
- 1.达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是, 0 表示否),此规则同样适用于 odps 建表。
说明: 任何字段如果为非负数,必须是 unsigned。
- 2.小数类型为 decimal,禁止使用 float 和 double。
说明: float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
- 3.表的命名最好是加上“ 业务名称_表的作用” ,避免上云梯后,再与其它业务表关联时有混淆。
正例: tiger_task / tiger_reader / mpp_config
- 4.单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明: 如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
- 5.字段允许适当冗余,以提高性能,但是必须考虑数据同步的情况。冗余字段应遵循:
1)不是频繁修改的字段。
2)不是 varchar 超长字段,更不能是 text 字段。
正例: 各业务线经常冗余存储商品名称,避免查询时需要调用 IC 服务获取
- 6.超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明: 即使双表 join 也要注意表索引、 SQL 性能。
- 7.页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明: 索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
- 8.如果有 order by 的场景,请注意利用索引的有序性(当order by 中的字段出现在where条件中时,才会利用索引(索引是有序的)而不排序)。 order by最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort的情况,影响查询性能。
正例: where a=? and b=? order by c; 索引: a_b_c
- 9.利用延迟关联或者子查询优化超多分页场景。
说明: MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。
正例: 先快速定位需要获取的 id 段,然后再关联: SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
- 10.建组合索引的时候,区分度最高的在最左边。
正例: 如果 where a=? and b=? , a 列的几乎接近于唯一值,那么只需要单建 idx_a 索引即可。
说明: 存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置。如: where a>?and b=? 那么即使 a 的区分度更高,也必须把 b 放在索引的最前列
- 11.不得使用外键与级联,一切外键概念必须在应用层解决。
说明: (概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,则为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
-
12.禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
-
13.in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个之内。
-
14.TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE无事务且不触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句。
-
15.
@Transactional事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等 -
16.表必备三字段: id(主键), gmt_create(创建时间), gmt_modified(修改时间)。更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间
五、安全规约
- 1.禁止向 HTML 页面输出未经安全过滤或未正确转义的用户数据。用户敏感数据禁止直接展示,必须对展示数据脱敏。
说明: 支付宝中查看个人手机号码会显示成:158**9119,隐藏中间 4 位,防止隐私泄露。
- 2.用户请求传入的任何参数必须做有效性验证。
说明: 忽略参数校验可能导致:
(1)page size 过大导致内存溢出
(2)恶意 order by 导致数据库慢查询
(3)正则输入源串拒绝服务 ReDOS
(4)任意重定向
(5)SQL 注入,用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定
(6)Shell 注入
(7)反序列化注入
-
3.表单、 AJAX 提交必须执行 CSRF 安全过滤。
-
4.发贴、评论、发送即时消息等用户生成内容的场景必须实现防刷、文本内容违禁词过滤等风控策略
参考资料
- 《阿里巴巴Java开发手册(公开版) 》