原文链接:我必须得告诉大家的MySQL优化原理
mysql处理请求sql的逻辑结构图
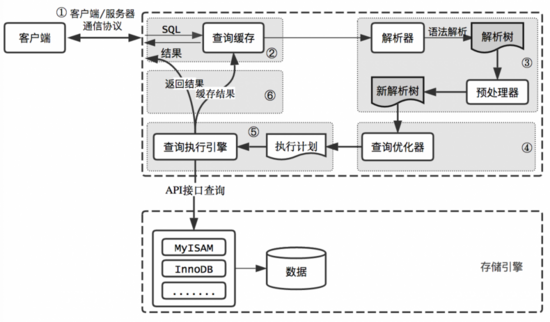
MySQL整个查询执行过程,总的来说分为6个步骤:
-
客户端向MySQL服务器发送一条查询请求
-
服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
-
服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
-
MySQL根据执行计划,调用存储引擎的API来执行查询
-
将结果返回给客户端,同时缓存查询结果
性能优化
-
通常来说把可为
NULL的列改为NOT NULL不会对性能提升有多少帮助,只是如果计划在列上创建索引,就应该将该列设置为NOT NULL。 -
对整数类型指定宽度,比如
INT(11),没有任何卵用。INT使用16为存储空间,那么它的表示范围已经确定,所以INT(1)和INT(20)对于存储和计算是相同的。 -
UNSIGNED表示不允许负值,大致可以使正数的上限提高一倍。比如TINYINT存储范围是-128 ~ 127,而UNSIGNED TINYINT存储的范围却是0 – 255。 -
通常来讲,没有太大的必要使用
DECIMAL数据类型。即使是在需要存储财务数据时,仍然可以使用BIGINT。比如需要精确到万分之一,那么可以将数据乘以一百万然后使用BIGINT存储。这样可以避免浮点数计算不准确和DECIMAL精确计算代价高的问题。 -
TIMESTAMP使用4个字节存储空间,DATETIME使用8个字节存储空间。因而,TIMESTAMP只能表示1970 – 2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。 -
大多数情况下没有使用枚举类型的必要,其中一个缺点是枚举的字符串列表是固定的,添加和删除字符串(枚举选项)必须使用
ALTER TABLE(如果只只是在列表末尾追加元素,不需要重建表)。 -
schema的列不要太多。原因是存储引擎的API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,这个转换过程的代价是非常高的。如果列太多而实际使用的列又很少的话,有可能会导致CPU占用过高。
-
大表
ALTER TABLE非常耗时,MySQL执行大部分修改表结果操作的方法是用新的结构创建一个张空表,从旧表中查出所有的数据插入新表,然后再删除旧表。尤其当内存不足而表又很大,而且还有很大索引的情况下,耗时更久。当然有一些奇淫技巧可以解决这个问题,有兴趣可自行查阅。 -
如果要统计行数,直接使用
COUNT(*),意义清晰,且性能更好。COUNT(1)则用于统计某个列值非NULL的数量。 -
在大数据场景下,表与表之间通过一个冗余字段来关联,要比直接使用
JOIN有更好的性能。
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
WHERE A.xx IN (5,6)
确保 ON 和 USING 字句中的列上有索引。在创建索引的时候就要考虑到关联的顺序。当表A和表B用列c关联的时候,如果优化器关联的顺序是A、B,那么就不需要在A表的对应列上创建索引。没有用到的索引会带来额外的负担,一般来说,除非有其他理由,只需要在关联顺序中的第二张表的相应列上创建索引(具体原因下文分析)。
确保任何的 GROUP BY 和 ORDER BY 中的表达式只涉及到一个表中的列,这样MySQL才有可能使用索引来优化。
- 优化LIMIT分页
有时候如果可以使用书签记录上次取数据的位置,那么下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用 OFFSET ,比如下面的查询:
SELECT id FROM t LIMIT 10000, 10;
改为:
SELECT id FROM t WHERE id > 10000 LIMIT 10;
其他优化的办法还包括使用预先计算的汇总表,或者关联到一个冗余表,冗余表中只包含主键列和需要做排序的列。
- 优化UNION
MySQL处理 UNION 的策略是先创建临时表,然后再把各个查询结果插入到临时表中,最后再来做查询。因此很多优化策略在 UNION 查询中都没有办法很好的时候。经常需要手动将 WHERE 、 LIMIT 、 ORDER BY 等字句“下推”到各个子查询中,以便优化器可以充分利用这些条件先优化。
- 索引的优化使用
1.MySQL不会使用索引的情况:非独立的列
select * from where id + 1 = 5
我们很容易看出其等价于 id = 4,但是MySQL无法自动解析这个表达式,使用函数是同样的道理。
2.前缀索引
如果列很长,通常可以索引开始的部分字符,这样可以有效节约索引空间,从而提高索引效率。
3.多列索引和索引顺序
不同版本的mysql对于多列索引的支持并不相同,所以多列索引有时候并不是好的选择,但如果需要使用多列索引,那么索引的顺序对于查询是至关重要的,很明显应该把选择性更高的字段放到索引的前面,这样通过第一个字段就可以过滤掉大多数不符合条件的数据。
索引选择性是指不重复的索引值和数据表的总记录数的比值,选择性越高查询效率越高,因为选择性越高的索引可以让MySQL在查询时过滤掉更多的行。唯一索引的选择性是1,这时最好的索引选择性,性能也是最好的。
以下sql是应该创建 (staff_id,customer_id) 的索引还是应该颠倒一下顺序?执行下面的查询,哪个字段的选择性更接近1就把哪个字段索引前面就好。
select count(distinct staff_id)/count(*) as staff_id_selectivity,
count(distinct customer_id)/count(*) as customer_id_selectivity,
count(*) from payment
4.避免多个范围条件
select user.* from user where login_time > '2017-04-01' and age between 18 and 30;
这个查询有一个问题:它有两个范围条件,login_time列和age列,MySQL可以使用login_time列的索引或者age列的索引,但无法同时使用它们。
5.覆盖索引
如果一个索引包含或者说覆盖所有需要查询的字段的值,那么就没有必要再回表查询,这就称为覆盖索引。
SELECT id, title, content FROM article
INNER JOIN (
SELECT id FROM article ORDER BY created DESC LIMIT 10000, 10
) AS page USING(id)
--索引建在created字段(其中id是主键)
6.使用索引扫描来排序
当索引的列顺序和 ORDER BY 子句的顺序完全一致,并且所有列的排序方向也一样时,才能够使用索引来对结果做排序。如果查询需要关联多张表,则只有 ORDER BY 子句引用的字段全部为第一张表时,才能使用索引做排序。 ORDER BY 子句和查询的限制是一样的,都要满足最左前缀的要求(有一种情况例外,就是最左的列被指定为常数,下面是一个简单的示例),其他情况下都需要执行排序操作,而无法利用索引排序。
---索引:(date,staff_id,customer_id),且最左列date为常数用作查询条件
select staff_id,customer_id from demo where date = '2015-06-01' order by staff_id,customer_id
7.冗余和重复索引
比如有一个索引 (A,B) ,再创建索引 (A) 就是冗余索引,应当尽量避免这种索引,发现后立即删除。大多数情况下都应该尽量扩展已有的索引而不是创建新索引。但有极少情况下出现性能方面的考虑需要冗余索引,比如扩展已有索引而导致其变得过大,从而影响到其他使用该索引的查询。
8.删除长期未使用的索引
定期删除一些长时间未使用过的索引是一个非常好的习惯。